10 months ago
The problem: Is the analogy between people reading books and becoming better authors and LLMs being trained on text valid?
Humans generate text. Language models also generate text. Humans learn from texts generated by others before they generate their own works. Language models learn from texts generated by others before they generate their own works. But do humans and LLMs learn in a way that is similar enough to make an analogy between how humans and language models use works of others to create their own work? This is an interesting philosophical question to investigate.
On 23/06/2025 a United States Court ruled that training LLMs on copyrighted books constitutes a fair use. I am not a lawyer, so I am not going to give legal advice by disputing the verdict based on the law of the United States; however, I am a philosopher, so I am going to give philosophical advice based on the law of logical analysis. The verdict is interesting philosophically because it is underlined by the aforementioned analogy and it is not entirely clear that the analogy is valid.
Andrew Ng, a machine learning researcher and well-known machine learning teacher who agrees with the court’s decision, made a similar claim at the beginning of 2024:
Just as humans are allowed to read articles posted online, learn from them, and then use what they learn to write brand-new articles, I would like to see computers allowed to do so, too.
Both claims seem to hinge on an idea that computers, like humans, may seek to extend their knowledge to produce better texts and, just like humans, they may choose one of the best ways to do that: reading a book written by someone else. They go to a shop, buy a book, read it and create a new text based on their reflections, becoming authors, much like children who read books. Of course it would be very naive to think that either Andrew Ng or the court had this scenario in mind when making their claims. However, this analogy makes it clear how humans and computers might learn from books in a similar way. Let us call it an uncontroversial upper bound and build a better understanding of how computers1 (LLMs) learn from text in reality.
LLMs are far from the situation just described. A newly initialized LLM is a model with no knowledge (technically speaking: random weights) and for this reason it can only produce random outputs. The first step in creating a useful large language model is to pretrain it on vast amounts of text - this is what Anthropic used the copyrighted data for. In this step, the texts are split into tokens (for simplicity let us assume that tokens are just cleaned up words, e.g. non-capitalized words without diacritics) and arranged into training samples, each containing a sequence of words and a word to predict. For example, the cited Andrew Ng’s text would be split into the following examples:
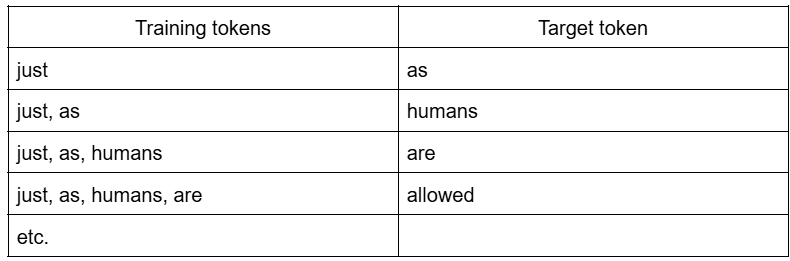
The words on the left are given to the model as input, the model makes a prediction and if it does not predict the target word, its weights are updated a little bit so that next time it is more likely that the model makes the correct prediction. It is quite obvious that if the model learns to predict the next word based on the previous words as it is presented in the table it will result in an awful model that always predicts “as” after the word “just” - it is far from what we expect from creative writing. This is where vast amounts of text come into play. When a model is fed an awful many sequences starting with “just, as”, it will at some point learn that there are many nouns that may come afterwards. Which noun (or any other part of speech) it will output depends on the probabilities of all next tokens given all previous tokens, randomness chosen by the user, etc. This way LLMs learn not only what words to use in which situations, but also how to put them together into a grammatically correct way (although probably it is more of a conceptual difference, in LLMs everything must be related to relative token probabilities and grammatically correct words should just be tokens with probabilities higher than grammatically incorrect words).
At this point this process looks a lot less like what people (children at school, for that matter) do when they are influenced by a copyrighted book they read. They read a book, think about it and create new texts inspired by the content of the book. They take a stance depending on the arguments that convince them and a network of beliefs they hold. When they copy a style they first have to think about the characteristic features the style has and notice what functions these features hold in the context of the text. Also, it would take a long time of practicing (and could potentially be harmful) to ensure a person acquires a style of a particular author and can use it without thinking too much about it. Language models on the other hand are provided vast amounts of data to learn statistical patterns and output text using these statistical patterns.
But, an opponent may say, “how do you know people’s brains do not undergo the same process as LLMs when they learn?” This is a conundrum that has already been covered quite extensively in literature and in less noble means of thought expression like Twitter. For example, Sam Altman, in a burst of philosophical inspiration, posted a 9(nine)-word philosophical tweet: “i am a stochastic parrot, and so r u.”2 The claims about humans being stochastic parrots just like LLMs are annoyingly contradictory. Before the LLM era, there was no mechanistic explanation of how humans produce language. But now, apparently, because there are language models that can produce text, some infer that the mechanism that leads to text generation in the case of humans and models must be the same. However, there are others that believe LLMs are not stochastic parrots and just because they were trained to do next-token prediction, it does not mean that is what they do when they generate text. This account would amount to saying that we know neither how humans nor how LLMs produce language; however, it is used to make us accept the same conclusion as before – that human and LLM language generation should be treated in a similar way3. Yet others, like Ilya Sutskever, for example, claim that it is the next token prediction that gives LLMs the power they have and that it is possible to surpass human knowledge using just this.
I do not wish to extend this discussion any further at the moment. For the sake of the argument, we can assume that human brains indeed perform the next-token prediction whose output we can see in speech and writing. If anything, this should make the problem of the doubtful analogy even more apparent. Humans are not trained on vast amounts of text before they are able to generate text, so at best it could be claimed that what LLMs acquire during pre-training is acquired by humans during many human lifetimes via evolution. It is another highly doubtful claim, but (again) I see no problem in making this assumption (if we do not make it, then the analogy between human and LLM learning will be even less apparent).
If humans are stochastic parrots whose language capabilities were acquired during evolution, just like language models acquire their language capabilities during pretraining, then the conclusion should be quite clear: at best, model pre-training could be analogous to evolutionary processes, not to humans learning new styles from books or writing creative text based on what they read somewhere else. If anything, it is retrieval-augmented generation that could be claimed to be more similar to these activities, and prima facie, it makes some sense. To be able to generate text in someone else’s style, one has to make a lot of conscious effort in order to keep it. In the case of LLMs, that would be keeping examples of someone else’s writing in the prompt and feeding them to an LLM before each text generation. LLM pre-training, however, would be similar to this alleged evolutionary process that endowed humans with linguistic capabilities, so it is more like creating new humans than teaching children at school.
Even a generous assumption is not enough to retain the analogy. But why is the assumption that pre-training is somehow similar to language evolution so debatable in the first place? It is fairly easy and it is enough to analyse the differences between the linguistic capabilities of a pre-trained LLM and a newborn, as a newborn human would be a human counterpart of a pre-trained LLM. When a human is born, one is not able to prompt them with a word and get a response like in the case of a language model. A pre-trained language model will most likely return words given the prompt; a newborn human will “return” “gu, gu, ga, ga” at best. A model needs further training to return outputs relevant to the prompt4, and a child needs a completely different type of language training before he/she is able to speak. The last stage of LLM development, Reinforcement Learning with Human Feedback (RLHF), “aligns” an LLM with human expectations about its answers5, and if anything, it is the closest to a child’s development; namely, adults also align children with adult values6. However, at this stage, the dataset used for the LLM training is created with human help (hence “Human Feedback” in the name), not by feeding the acquired (one way or another) texts to the model.
So, does this mean that some of the propositions from the very beginning of this article are false? Not really. The problem is that to accept that both humans and language models learn from texts written by others means not to recognize the equivocal nature of the word “learn.” It is not hard to show (as I attempted in this article) that the word “learn” means something different in the context of human learning and LLM learning and as such cannot be a basis for a useful analogy. Unfortunately, both Andrew Ng’s claim and the ruling of the court are based on this overlooked equivocation. And my claim is true even if, due to a coincidence that is both hard to imagine and explain, both humans and LLMs end up with the same mechanism for language generation.
Does this mean that the ruling was incorrect? Of course not; as mentioned at the beginning, it is not legal advice. It is possible that the law (of any country) is not ready for the way language (and any other) models “learn” from vast amounts of data, and because of that, companies like Anthropic do not break any law when building systems using life’s work of other people for their own profit, systems that would otherwise be useless at worst or not suitable for some of their uses7 at best. Maybe they did break the law, because it is they (Anthropic) who are the subject of possible misuse of copyrighted data, not computers that allegedly just want to learn from books like humans. But I am getting ahead of myself. My philosophical advice amounted to showing that when we speak using high-level language about how humans and LLMs acquire their language skills, the word “learn” overshadows two very different processes and as such cannot be a basis for making substantial claims about the similarity of humans and language models.
1 The “computers” mentioned by Andrew Ng are really just Large Language Models, so from now on I will speak only of LLMs.
2 https://x.com/sama/status/1599471830255177728
3 It is worth noting that the truth value of the statement ‘NA = NA’ is NA, not T.
4 For example, to answer questions.
5 For example, politeness and helpfulness.
6 Of course, these two processes are also very different, but that is not relevant here as it does not change the main argument of this article.
7 Like mimicking the writing of some authors.