2 years ago
In the modern business landscape, the quest for efficient, accurate and responsive digital interaction platforms is relentless. Companies are increasingly looking towards Large Language Models (LLMs) to enhance their customer services, to optimise their internal documentation processes and to create compelling content across various channels. The question is no longer whether or not to implement an LLM, but how to do so in a way that aligns best with your company's operational and financial standards.
The business case for LLMs: A multi-faceted approach
The potential applications of LLMs within a business are vast and varied, and the benefits are clear. LLMs can answer client queries via a chatbot, search through heaps of technical documentation for specific information and generate engaging content for social media, public relations and human resources. But how can a company unlock these benefits effectively?
The answer may lie in the choice between deploying an LLM through a third-party hosted service or hosting it locally. While both approaches offer advantages, the decision hinges on critical factors such as data privacy, cost and customization.
Data privacy: The highest priority
One of the paramount concerns for any organisation is safeguarding sensitive information. By hosting LLMs on local servers, companies gain full control over their data, which minimises the risk of exposure to third parties. This approach is crucial for industries bound by stringent data protection regulations that ensure that all interactions remain confidential and secure.
Cost efficiency: A calculated approach
Deploying LLMs locally can significantly reduce operational expenses. Although cloud services are flexible, such services often come with pricing models based on resource consumption or hours of usage. For organisations that are able to manage their own infrastructure, local deployment eliminates these variable costs, which offers a more predictable, and often less expensive, structure.
Customization: Tailoring for precision
Every business has unique needs and challenges. Local LLMs can be fine-tuned with proprietary data, allowing for models that are highly specialised and effective for specific use cases. Whether it's enhancing customer interaction, streamlining document analysis or generating targeted content, a bespoke model can deliver superior performance by learning from the exact data that it will be applied to.
Talking to your data: The evolution of business intelligence
Fine-tuning: The precise approach
Fine-tuning is a process that involves training a pre-trained model on a new, carefully curated dataset that is specific to a particular task, such as following instructions or answering questions. This method allows the model to adapt its knowledge in order to perform better on tasks that are directly relevant to the business's needs. While fine-tuning can significantly enhance the model's performance on specialised tasks, it comes with its own set of challenges:
Computational expense:
Fine-tuning large models requires substantial computational resources, which makes it a costly endeavour for many organisations.
Catastrophic forgetting:
There's a risk that the model might lose previously learned information in the process of acquiring new knowledge, a phenomenon that is known as "catastrophic forgetting". This can result in the model performing less well after fine-tuning than it did before fine-tuning took place.
Low-rank adaptation: The efficient alternative
As an alternative to the resource-intensive, full-parameter fine-tuning process, Low-Rank Adaptation (LoRA) offers a promising solution. LoRA operates by introducing lightweight adapters to a pre-existing model without altering the original model weights. This approach has several advantages.
Efficiency:
By not modifying the original model weights, LoRA is significantly more computationally efficient compared to traditional fine-tuning.
Preservation of knowledge:
Since the core model remains unchanged, LoRA mitigates the risk of catastrophic forgetting, which ensures that the model retains its original capabilities, but also gains new knowledge.
Comparable performance:
Despite the smaller number of parameters being adjusted, models trained with LoRA demonstrate performance levels that are similar to fully fine-tuned models, which makes it an attractive option for businesses that want to enhance their LLMs without the associated costs and risks.
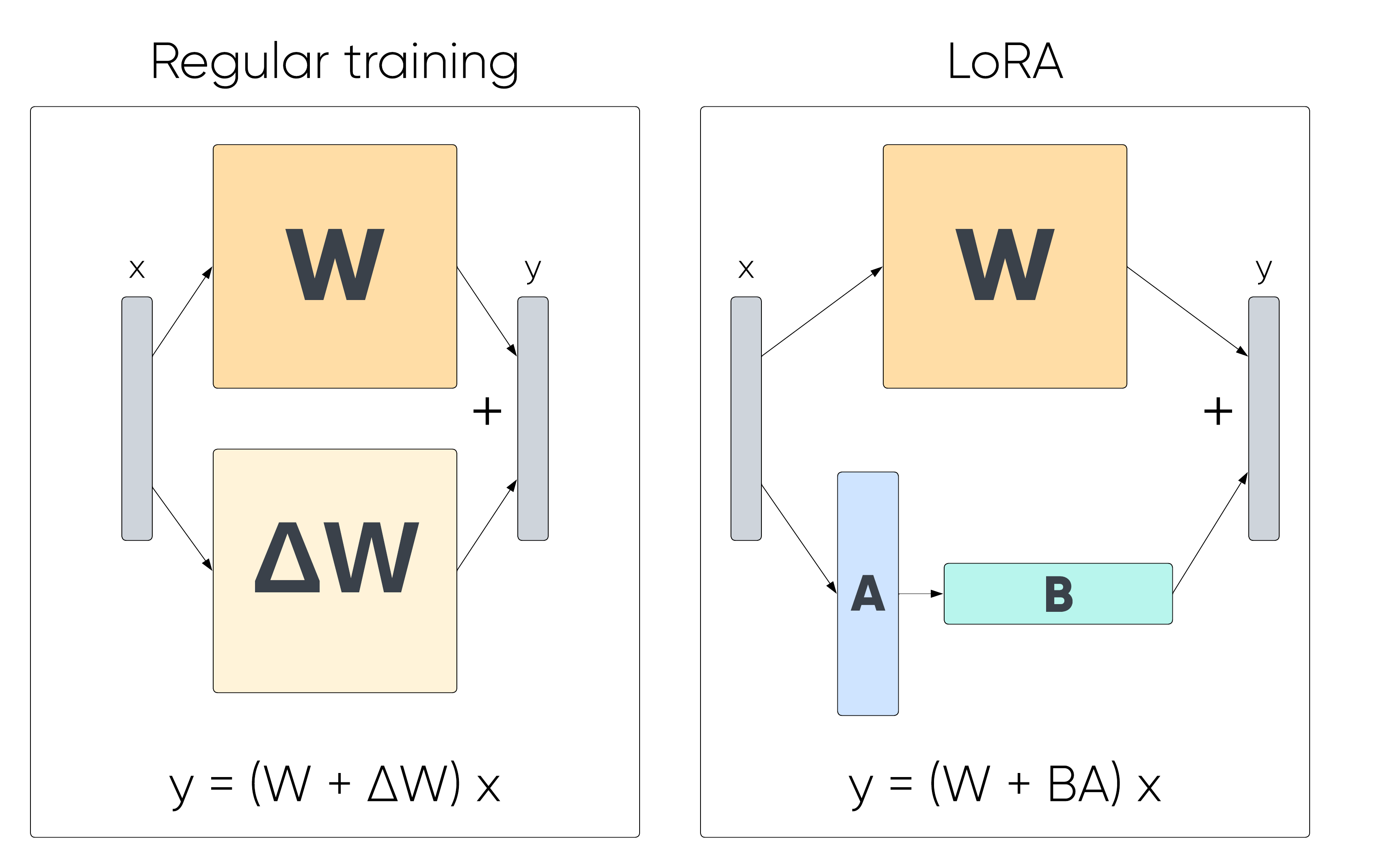
Adapting to new tasks with ease
The concept of quickly changing the task mode of a LLM by simply changing its adapter is a powerful and flexible approach to leveraging artificial intelligence in business and technology applications. Adapters enable a seamless transition between different task modes, such as from the task of generating customer service responses to the task of either creating personalised marketing content or analysing complex technical documents. This adaptability allows organisations to repurpose a single, pre-trained model across a variety of tasks with minimal effort and computational cost.
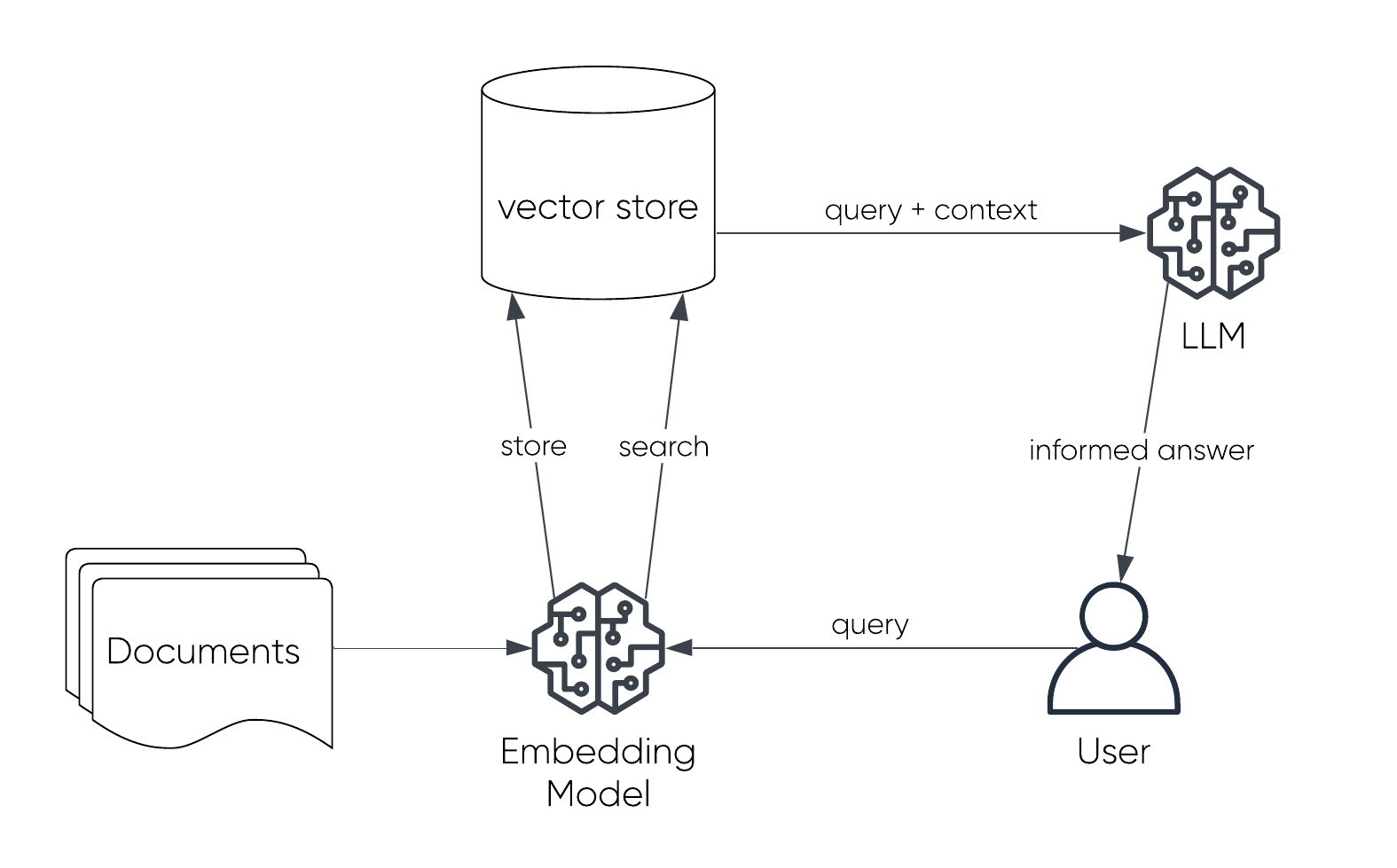
Retrieval-Augmented Generation: Expanding knowledge horizons
Retrieval-Augmented Generation (RAG) introduces a configuration that combines the generative capabilities of LLMs with an information retrieval component. This setup makes it possible for the model to pull in external data that is relevant to a user’s query, and therefore the model can offer answers that are not limited to the model's training data. The process involves:
Converting documents into embeddings:
This step transforms all available documents into vector representations, which makes the documents searchable by the model.
Generating a query embedding:
The user’s query is also converted into an embedding.
Retrieving relevant context:
The document embeddings that are most similar to the query embedding are retrieved and served as contextual input for the LLM.
Generating an informed answer:
The LLM uses the query combined with the retrieved context to produce a response grounded in external data.
This approach is particularly useful for grounding LLM responses in the most recently available data or in domain-specific knowledge that the LLM was not originally trained on.
Preparing data for RAG: Navigating complexities
The preparation of data for RAG is a meticulous process that involves converting documents into a format that can be efficiently processed by the model. This typically means transforming documents into raw text and then segmenting this text into manageable chunks. However, this task can present unique challenges, especially when dealing with data in complex formats such as tables, images, or audio. Successfully navigating these challenges is crucial if you want to leverage RAG to its full potential.
Converting complex data formats
Tables:
Converting tabular data into text requires a strategy that preserves the inherent relationships and contextual information. This might involve creating descriptive narratives or summarising key data points in a textual format that maintains the essence of the information.
Images and Audio:
For content like images and audio, the use of additional AI tools capable of converting these formats into descriptive text is necessary. This could involve Optical Character Recognition (OCR) for images and speech-to-text algorithms for audio, followed by a contextual interpretation layer to ensure that the converted text is meaningful for the RAG process.
Key considerations in data preparation
When preparing data for RAG, several critical factors must be taken into account to ensure that the process aligns with the intended outcomes of the LLM's tasks.
Chunk length
The length of the text chunks into which documents are segmented plays a significant role in the model's performance. This length should be carefully chosen, based on the embedding model and LLM context lengths.
Overlap between chunks
Incorporating overlap between consecutive text chunks can ensure that no critical information is lost or contextually isolated. This strategy helps maintain continuity and coherence in the model's understanding and output.
Choosing the best embedding model
It is crucial to select the most appropriate embedding model, which should be tailored to the specific requirements of the task at hand.
Semantic similarity: For tasks requiring an understanding of textual nuances and similarities, simpler embeddings trained on semantic similarity can be effective.
Query-Answer matching: For applications that focus on retrieving precise answers to queries, sentence embeddings that are fine-tuned for semantic search are a better approach. These models are specifically optimised to understand the intent behind queries and to match them with the most relevant answers.
The effective deployment of RAG hinges on the careful selection of its components and parameters, tailored specifically to the demands of each use case. High precision in customization is crucial for aligning the RAG system's capabilities with the specific requirements.
How retrieval works in an embedding space
The retrieval process involves searching for the closest document embeddings to the query embedding within the high-dimensional vector space, which is typically done by using similarity measures such as cosine similarity. The search results in a list of 'nearest neighbours', which are the document embeddings most similar to the query embedding. These documents are considered to be the most relevant to the query.
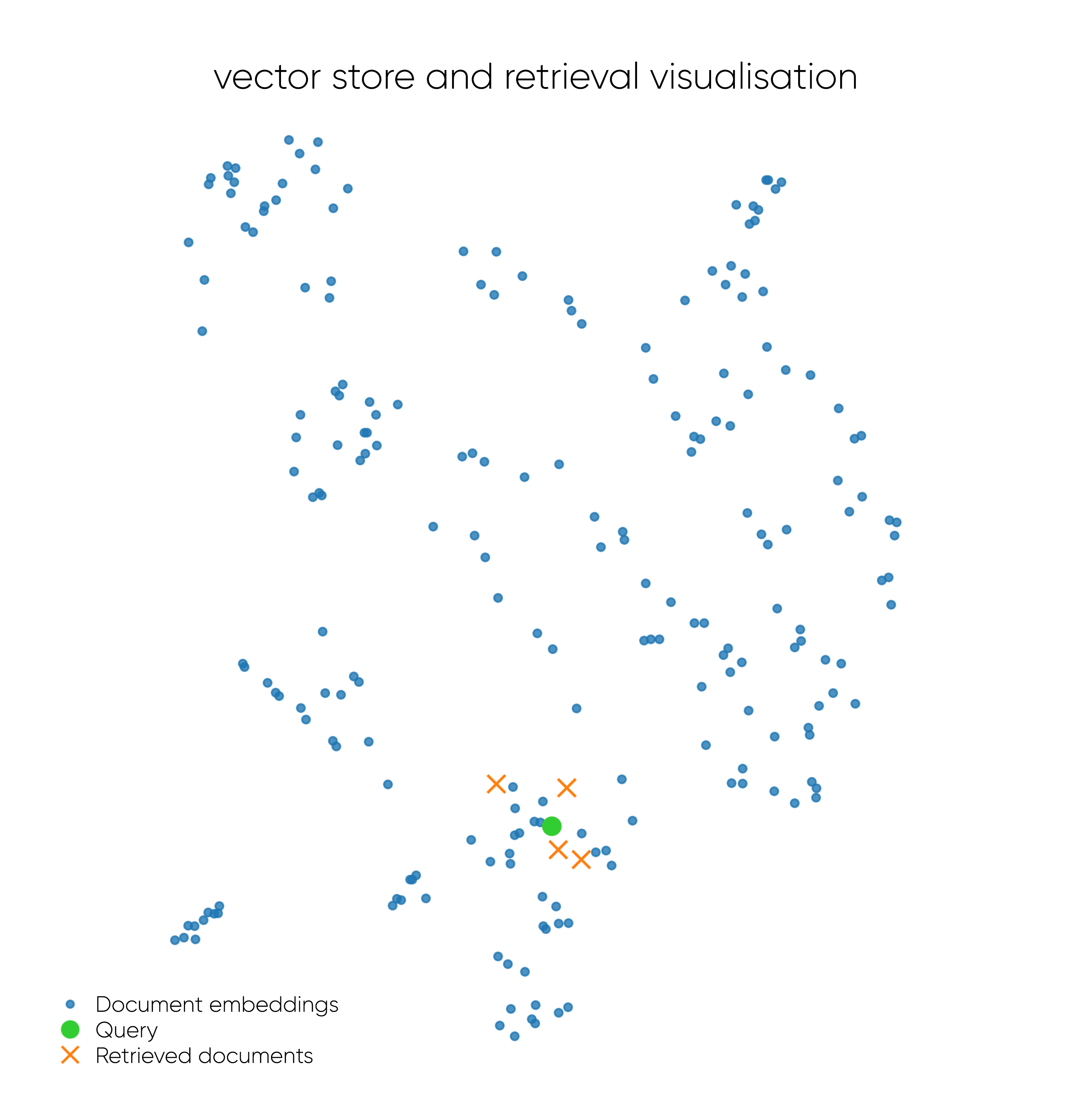
The visualisation above illustrates a vector store that is reduced to a 2D-representation, along with retrieval results.
Case Study: Enhancing insurance documentation queries with RAG and fine-tuning
In the world of insurance, clarity and precision in documentation are paramount. To illustrate the transformative power of Retrieval-Augmented Generation coupled with fine-tuning, we worked on the following project. Our goal was to develop a RAG application that could navigate the complexities of insurance documentation and provide precise answers to specific queries.
Assembling the Dataset
We curated a dataset from the insurance documentation, comprising question-answer pairs that represent real-world inquiries that one might encounter in the industry.
Example Q&A pair from the dataset:
Q: Who can modify the terms of this insurance policy?
A: Changes to this Group Policy can only be authorised by an officer of The Principal, and must be formally documented in writing and signed by such an officer to take effect.
The developed RAG application utilises an open-source embedding model and our custom fine-tuned model, Mistral-7B-concise, which we specifically optimised to produce succinct answers. To assess its performance, we compared usage with the same RAG setup, but with two other LLM components, Mistral-7B-instruct and gpt-3.5-turbo.
Evaluating the models
To test the models, we posed a series of questions that were directly related to the insurance policy documentation. Here's an extract of the questions that we asked and the answers that each model provided:
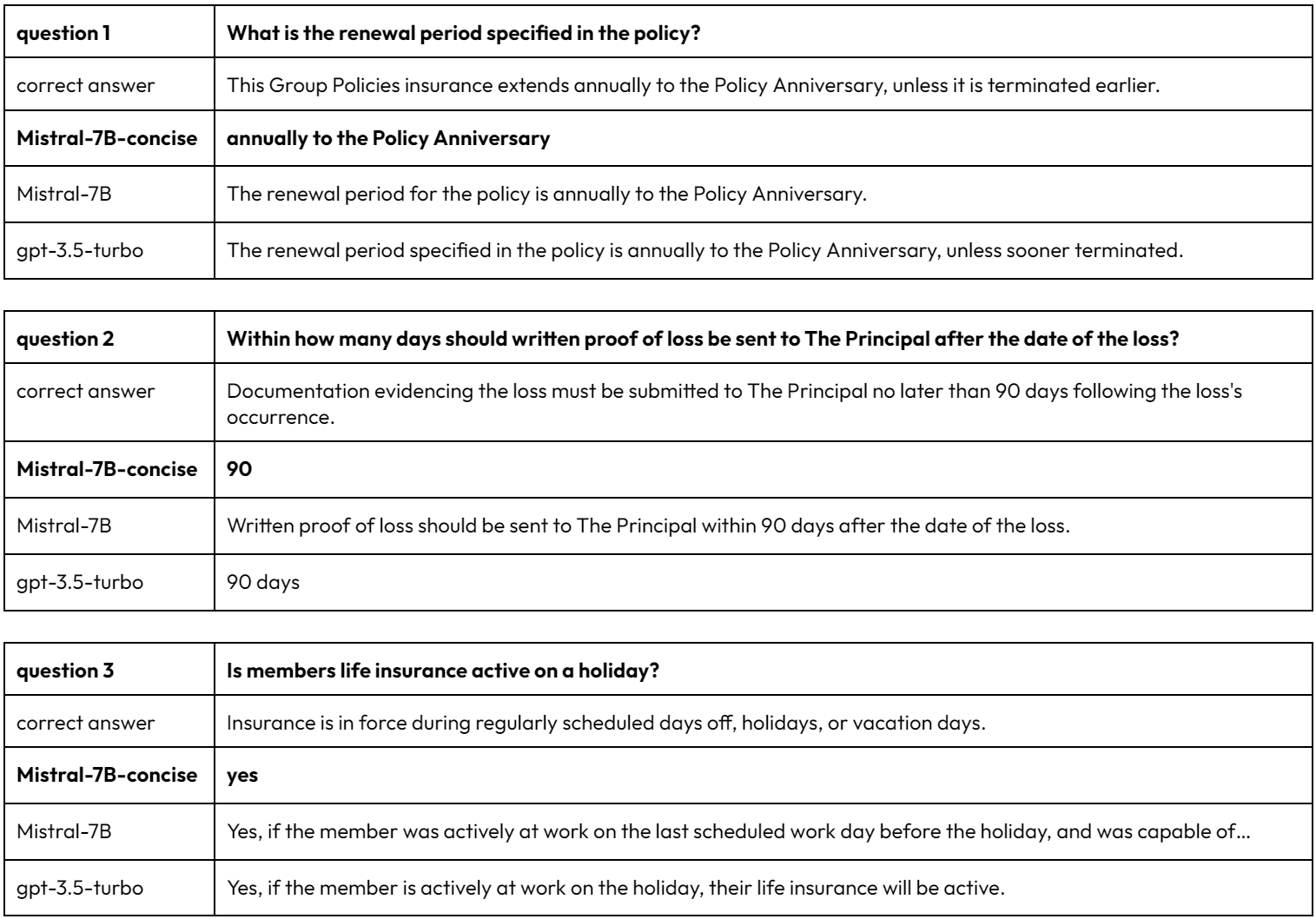
In evaluating our RAG application, the custom fine-tuned Mistral-7B-concise performed as intended, delivering precise answers, which demonstrates the practical benefits of RAG and fine-tuning. This project highlights the effectiveness of tailored language models in streamlining complex information retrieval tasks.
The Digital Age: Stay Competitive
In an era where technological advancement shapes the business landscape, staying competitive necessitates embracing innovation and digital transformation. The strategic integration of Large Language Models into business operations represents a forward-thinking approach to this challenge. By enhancing customer service, streamlining documentation and generating dynamic content, LLMs offer businesses unique leverage. Adaptability and the continuous exploration of technological solutions, such as fine-tuning and Retrieval-Augmented Generation, lets companies maintain relevance and leadership in the digital age. By harnessing the potential of LLMs, businesses can not only optimise their current processes, but also pave the way for future innovations, ensuring their place at the forefront of their industry.
Edward J. Hu, Yelong Shen, Phillip Wallis, et al., ‘LoRA: Low-Rank Adaptation of Large Language Models’, https://doi.org/10.48550/arXiv.2106.09685
Patrick Lewis, Ethan Perez, Aleksandra Piktus, et al., ‘Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks’ https://doi.org/10.48550/arXiv.2005.11401
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, Luke Zettlemoyer, ‘QLoRA: Efficient Finetuning of Quantized LLMs’, https://doi.org/10.48550/arXiv.2305.14314
Yun Luo, Zhen Yang, Fandong Meng, et al., ‘An Empirical Study of Catastrophic Forgetting in Large Language Models During Continual Fine-tuning’, https://doi.org/10.48550/arXiv.2308.08747